Information in this document may be out of date
This document has an older update date than the original, so the information it contains may be out of date. If you're able to read English, see the English version for the most up-to-date information: Logging Architecture
Log di registrazione
I log di applicazioni e sistemi possono aiutarti a capire cosa sta accadendo all'interno del tuo cluster. I log sono particolarmente utili per il debug dei problemi e il monitoraggio delle attività del cluster. La maggior parte delle applicazioni moderne ha una sorta di meccanismo di registrazione; in quanto tale, la maggior parte dei motori di container sono progettati allo stesso modo per supportare alcuni tipi di registrazione. Il metodo di registrazione più semplice e più accettato per le applicazioni containerizzate è scrivere sull'output standard e sui flussi di errore standard.
Tuttavia, la funzionalità nativa fornita da un motore contenitore o dal runtime di solito non è sufficiente per una soluzione di registrazione completa. Ad esempio, se un container si arresta in modo anomalo, un pod viene rimosso, o un nodo muore, di solito vuoi comunque accedere ai log dell'applicazione. Pertanto, i registri devono avere una memoria e un ciclo di vita separati, indipendenti da nodi, pod o contenitori. Questo concetto è chiamato cluster-logging. La registrazione a livello di cluster richiede un back-end separato per archiviare, analizzare e interrogare i registri. Kubernetes non fornisce alcuna soluzione di archiviazione nativa per i dati di registro, ma è possibile integrare molte soluzioni di registrazione esistenti nel proprio cluster Kubernetes.
Le architetture di registrazione a livello di cluster sono descritte nel presupposto che un back-end per la registrazione è presente all'interno o all'esterno del cluster. Se tu sei non interessa avere la registrazione a livello di cluster, potresti ancora trovarlo la descrizione di come i registri sono memorizzati e gestiti sul nodo per essere utile.
Basic logging in Kubernetes
In questa sezione, puoi vedere un esempio di registrazione di base in Kubernetes emette i dati sul flusso di output standard. Utilizza questa dimostrazione una specifica pod con un contenitore che scrive del testo sullo standard output una volta al secondo.

apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args: [/bin/sh, -c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done']
Per eseguire questo pod, utilizzare il seguente comando:
$ kubectl create -f https://k8s.io/examples/debug/counter-pod.yaml
pod/counter created
Per recuperare i registri, usa il comando kubectl logs, come segue:
$ kubectl logs counter
0: Mon Jan 1 00:00:00 UTC 2001
1: Mon Jan 1 00:00:01 UTC 2001
2: Mon Jan 1 00:00:02 UTC 2001
...
You can use kubectl logs to retrieve logsPuoi usare kubectl logs per recuperare i log da una precedente istanziazione di un contenitore con il flag --previous, nel caso in cui il contenitore si sia arrestato in modo anomalo. Se il pod ha più contenitori, è necessario specificare i registri del contenitore a cui si desidera accedere aggiungendo un nome contenitore al comando. Vedi la documentazione kubectl logs per maggiori dettagli. from a previous instantiation of a container with --previous flag, in case the container has crashed. If your pod has multiple containers, you should specify which container's logs you want to access by appending a container name to the command. See the kubectl logs documentation for more details.
Logging at the node level
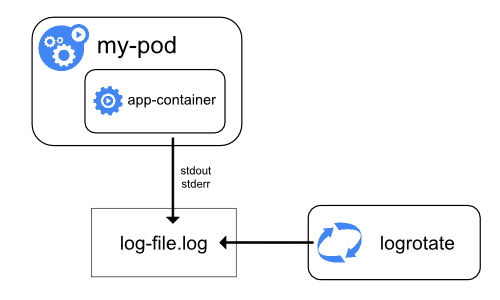{kind=link}
Tutto ciò che una applicazione containerizzata scrive su stdout e stderr viene gestito e reindirizzato da qualche parte da un motore contenitore. Ad esempio, il motore del contenitore Docker reindirizza questi due flussi a un driver di registrazione, che è configurato in Kubernetes per scrivere su un file in formato json .
Di default, se un container si riavvia, kubelet mantiene un container terminato con i suoi log. Se un pod viene espulso dal nodo, tutti i contenitori corrispondenti vengono espulsi, insieme ai loro log.
Una considerazione importante nella registrazione a livello di nodo sta implementando la rotazione dei log,
in modo che i registri non consumino tutta la memoria disponibile sul nodo. kubernetes
al momento non è responsabile della rotazione dei registri, ma piuttosto di uno strumento di distribuzione
dovrebbe creare una soluzione per affrontarlo.
Ad esempio, nei cluster di Kubernetes, implementato dallo script kube-up.sh,
c'è un logrotate
strumento configurato per funzionare ogni ora. È anche possibile impostare un runtime del contenitore su
ruotare automaticamente i registri dell'applicazione, ad es. usando il log-opt di Docker.
Nello script kube-up.sh, quest'ultimo approccio viene utilizzato per l'immagine COS su GCP,
e il primo approccio è usato in qualsiasi altro ambiente. In entrambi i casi, da
la rotazione predefinita è configurata per essere eseguita quando il file di registro supera 10 MB.
Ad esempio, puoi trovare informazioni dettagliate su come kube-up.sh imposta
up logging per l'immagine COS su GCP nello [script] cosConfigureHelper corrispondente.
Quando esegui kubectl logs come in
l'esempio di registrazione di base, il kubelet sul nodo gestisce la richiesta e
legge direttamente dal file di log, restituendo il contenuto nella risposta.
log di kubectl. Per esempio. se c'è un file da 10 MB, esegue logrotate
la rotazione e ci sono due file, uno da 10 MB e uno vuoto,
kubectl logs restituirà una risposta vuota.
System component logs
Esistono due tipi di componenti di sistema: quelli che vengono eseguiti in un contenitore e quelli che non funziona in un contenitore. Per esempio:
- Lo scheduler di Kubernetes e il proxy kube vengono eseguiti in un contenitore.
- Il kubelet e il runtime del contenitore, ad esempio Docker, non vengono eseguiti nei contenitori.
Sulle macchine con systemd, il kubelet e il runtime del contenitore scrivono su journal. Se
systemd non è presente, scrive nei file .log nella directory/var/log.
I componenti di sistema all'interno dei contenitori scrivono sempre nella directory /var/log,
bypassando il meccanismo di registrazione predefinito. Usano il klog klog
biblioteca di registrazione. È possibile trovare le convenzioni per la gravità della registrazione per quelli
componenti nel documento di sviluppo sulla registrazione.
Analogamente ai log del contenitore, i log dei componenti di sistema sono in /var/log
la directory dovrebbe essere ruotata. Nei cluster di Kubernetes allevati da
lo script kube-up.sh, quei log sono configurati per essere ruotati da
lo strumento logrotate al giorno o una volta che la dimensione supera i 100 MB.
Cluster-level logging architectures
Sebbene Kubernetes non fornisca una soluzione nativa per la registrazione a livello di cluster, esistono diversi approcci comuni che è possibile prendere in considerazione. Ecco alcune opzioni:
- Utilizzare un agente di registrazione a livello di nodo che viene eseguito su ogni nodo.
- Includere un contenitore sidecar dedicato per l'accesso a un pod di applicazione.
- Invia i registri direttamente a un back-end dall'interno di un'applicazione.
Using a node logging agent
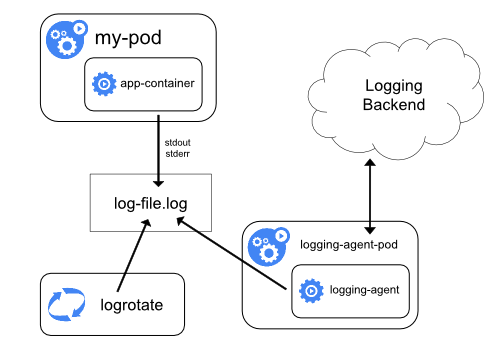
È possibile implementare la registrazione a livello di cluster includendo un agente di registrazione a livello node su ciascun nodo. L'agente di registrazione è uno strumento dedicato che espone i registri o trasferisce i registri a un back-end. Comunemente, l'agente di registrazione è un contenitore che ha accesso a una directory con file di registro da tutti i contenitori delle applicazioni su quel nodo.
Poiché l'agente di registrazione deve essere eseguito su ogni nodo, è comune implementarlo come una replica DaemonSet, un pod manifest o un processo nativo dedicato sul nodo. Tuttavia, questi ultimi due approcci sono deprecati e altamente scoraggiati.
L'utilizzo di un agent di registrazione a livello di nodo è l'approccio più comune e consigliato per un cluster Kubernetes, poiché crea solo un agente per nodo e non richiede alcuna modifica alle applicazioni in esecuzione sul nodo. Tuttavia, la registrazione a livello di nodo funziona solo per l'output standard delle applicazioni e l'errore standard.
Kubernetes non specifica un agente di registrazione, ma due agenti di registrazione facoltativi sono impacchettati con la versione di Kubernetes: Stackdriver Logging da utilizzare con Google Cloud Platform e Elasticsearch. Puoi trovare ulteriori informazioni e istruzioni nei documenti dedicati. Entrambi usano fluentd con configurazione personalizzata come agente sul nodo.
Using a sidecar container with the logging agent
Puoi utilizzare un contenitore sidecar in uno dei seguenti modi:
- Il contenitore sidecar trasmette i log delle applicazioni al proprio
stdout. - Il contenitore sidecar esegue un agente di registrazione, che è configurato per raccogliere i registri da un contenitore di applicazioni.
Streaming sidecar container
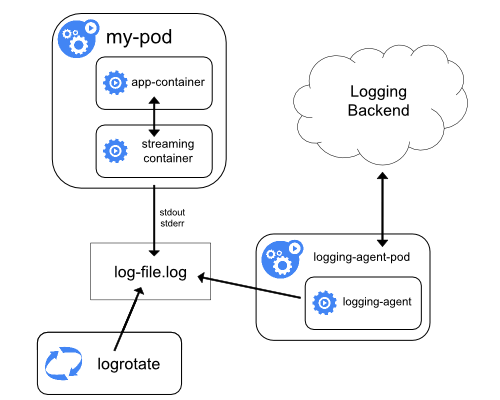
Facendo scorrere i propri contenitori sidecar sul proprio stdout e stderr
flussi, è possibile sfruttare il kubelet e l'agente di registrazione che
già eseguito su ciascun nodo. I contenitori del sidecar leggono i log da un file, un socket,
o il diario. Ogni singolo contenitore sidecar stampa il log nel proprio stdout
o flusso stderr.
Questo approccio consente di separare diversi flussi di log da diversi
parti della tua applicazione, alcune delle quali possono mancare di supporto
per scrivere su stdout o stderr. La logica dietro il reindirizzamento dei registri
è minimo, quindi non è un sovraccarico significativo. Inoltre, perché
stdout e stderr sono gestiti da kubelet, puoi usare gli strumenti integrati
come log di kubectl.
Considera il seguente esempio. Un pod esegue un singolo contenitore e il contenitore scrive su due file di registro diversi, utilizzando due formati diversi. Ecco un file di configurazione per il pod:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
Sarebbe un disastro avere voci di registro di diversi formati nello stesso registro
stream, anche se si è riusciti a reindirizzare entrambi i componenti al flusso stdout di
Il container. Invece, potresti introdurre due container sidecar. Ogni sidecar
contenitore potrebbe accodare un particolare file di registro da un volume condiviso e quindi reindirizzare
i registri al proprio flusso stdout.
Ecco un file di configurazione per un pod con due contenitori sidecar:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-1
image: busybox
args: [/bin/sh, -c, 'tail -n+1 -f /var/log/1.log']
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-2
image: busybox
args: [/bin/sh, -c, 'tail -n+1 -f /var/log/2.log']
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
Ora quando si esegue questo pod, è possibile accedere separatamente a ciascun flusso di log eseguendo i seguenti comandi:
$ kubectl logs counter count-log-1
0: Mon Jan 1 00:00:00 UTC 2001
1: Mon Jan 1 00:00:01 UTC 2001
2: Mon Jan 1 00:00:02 UTC 2001
...
$ kubectl logs counter count-log-2
Mon Jan 1 00:00:00 UTC 2001 INFO 0
Mon Jan 1 00:00:01 UTC 2001 INFO 1
Mon Jan 1 00:00:02 UTC 2001 INFO 2
...
L'agente a livello di nodo installato nel cluster preleva tali flussi di log automaticamente senza alcuna ulteriore configurazione. Se ti piace, puoi configurare l'agente per analizzare le righe di registro in base al contenitore di origine.
Si noti che, nonostante il basso utilizzo della CPU e della memoria (ordine di un paio di millesimi
per cpu e ordine di diversi megabyte per memoria), scrivere registri su un file e
quindi il loro streaming su stdout può raddoppiare l'utilizzo del disco. Se hai
un'applicazione che scrive in un singolo file, è generalmente meglio impostare
/dev/stdout come destinazione piuttosto che implementare il sidecar streaming
approccio contenitore.
I contenitori del sidecar possono anche essere usati per ruotare i file di log che non possono essere
ruotato dall'applicazione stessa. Un esempio
di questo approccio è un piccolo contenitore che esegue periodicamente logrotate.
Tuttavia, si raccomanda di usare stdout e stderr direttamente e lasciare la rotazione
e politiche di conservazione al kubelet.
Sidecar container with a logging agent
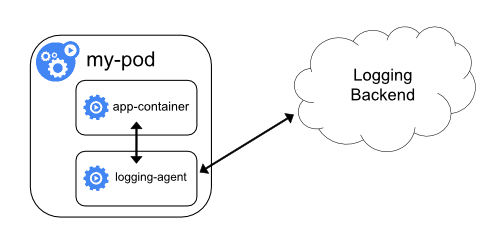
Se l'agente di registrazione a livello di nodo non è abbastanza flessibile per la tua situazione, tu puoi creare un container sidecar con un logger separato che hai configurato specificamente per essere eseguito con la tua applicazione.
kubectl logs, perché non sono controllati
dal kubelet.
Ad esempio, è possibile utilizzare Stackdriver, che utilizza fluentd come agente di registrazione. Qui ci sono due file di configurazione puoi usare per implementare questo approccio. Il primo file contiene a ConfigMap per configurare fluentd.
apiVersion: v1
kind: ConfigMap
metadata:
name: fluentd-config
data:
fluentd.conf: |
<source>
type tail
format none
path /var/log/1.log
pos_file /var/log/1.log.pos
tag count.format1
</source>
<source>
type tail
format none
path /var/log/2.log
pos_file /var/log/2.log.pos
tag count.format2
</source>
<match **>
type google_cloud
</match>
Il secondo file descrive un pod con un contenitore sidecar in esecuzione fluentd. Il pod monta un volume dove fluentd può raccogliere i suoi dati di configurazione.
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-agent
image: registry.k8s.io/fluentd-gcp:1.30
env:
- name: FLUENTD_ARGS
value: -c /etc/fluentd-config/fluentd.conf
volumeMounts:
- name: varlog
mountPath: /var/log
- name: config-volume
mountPath: /etc/fluentd-config
volumes:
- name: varlog
emptyDir: {}
- name: config-volume
configMap:
name: fluentd-config
Dopo un po 'di tempo è possibile trovare i messaggi di registro nell'interfaccia Stackdriver.
Ricorda che questo è solo un esempio e puoi effettivamente sostituire fluentd con qualsiasi agente di registrazione, leggendo da qualsiasi fonte all'interno di un'applicazione contenitore.
Exposing logs directly from the application
È possibile implementare la registrazione a livello di cluster esponendo o spingendo i registri direttamente da ogni applicazione; tuttavia, l'implementazione di un tale meccanismo di registrazione è al di fuori dello scopo di Kubernetes.