Kubernetes 1.30: Beta Support For Pods With User Namespaces
Linux provides different namespaces to isolate processes from each other. For example, a typical Kubernetes pod runs within a network namespace to isolate the network identity and a PID namespace to isolate the processes.
One Linux namespace that was left behind is the user namespace. This namespace allows us to isolate the user and group identifiers (UIDs and GIDs) we use inside the container from the ones on the host.
This is a powerful abstraction that allows us to run containers as "root": we are root inside the container and can do everything root can inside the pod, but our interactions with the host are limited to what a non-privileged user can do. This is great for limiting the impact of a container breakout.
A container breakout is when a process inside a container can break out onto the host using some unpatched vulnerability in the container runtime or the kernel and can access/modify files on the host or other containers. If we run our pods with user namespaces, the privileges the container has over the rest of the host are reduced, and the files outside the container it can access are limited too.
In Kubernetes v1.25, we introduced support for user namespaces only for stateless pods. Kubernetes 1.28 lifted that restriction, and now, with Kubernetes 1.30, we are moving to beta!
What is a user namespace?
Note: Linux user namespaces are a different concept from Kubernetes namespaces. The former is a Linux kernel feature; the latter is a Kubernetes feature.
User namespaces are a Linux feature that isolates the UIDs and GIDs of the containers from the ones on the host. The identifiers in the container can be mapped to identifiers on the host in a way where the host UID/GIDs used for different containers never overlap. Furthermore, the identifiers can be mapped to unprivileged, non-overlapping UIDs and GIDs on the host. This brings two key benefits:
-
Prevention of lateral movement: As the UIDs and GIDs for different containers are mapped to different UIDs and GIDs on the host, containers have a harder time attacking each other, even if they escape the container boundaries. For example, suppose container A runs with different UIDs and GIDs on the host than container B. In that case, the operations it can do on container B's files and processes are limited: only read/write what a file allows to others, as it will never have permission owner or group permission (the UIDs/GIDs on the host are guaranteed to be different for different containers).
-
Increased host isolation: As the UIDs and GIDs are mapped to unprivileged users on the host, if a container escapes the container boundaries, even if it runs as root inside the container, it has no privileges on the host. This greatly protects what host files it can read/write, which process it can send signals to, etc. Furthermore, capabilities granted are only valid inside the user namespace and not on the host, limiting the impact a container escape can have.
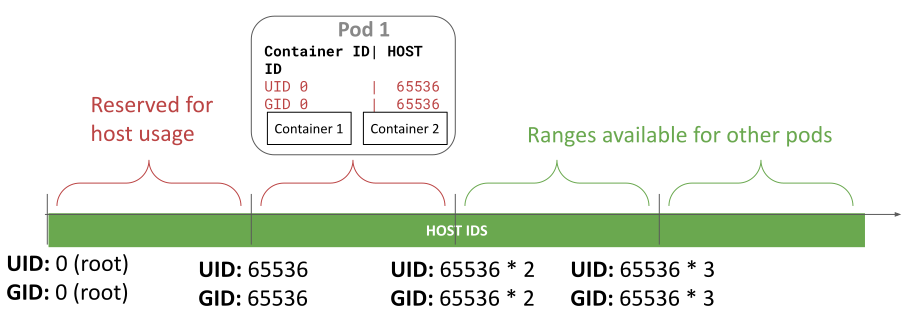
User namespace IDs allocation
Without using a user namespace, a container running as root in the case of a container breakout has root privileges on the node. If some capabilities were granted to the container, the capabilities are valid on the host too. None of this is true when using user namespaces (modulo bugs, of course 🙂).
Changes in 1.30
In Kubernetes 1.30, besides moving user namespaces to beta, the contributors working on this feature:
- Introduced a way for the kubelet to use custom ranges for the UIDs/GIDs mapping
- Have added a way for Kubernetes to enforce that the runtime supports all the features needed for user namespaces. If they are not supported, Kubernetes will show a clear error when trying to create a pod with user namespaces. Before 1.30, if the container runtime didn't support user namespaces, the pod could be created without a user namespace.
- Added more tests, including tests in the cri-tools repository.
You can check the documentation on user namespaces for how to configure custom ranges for the mapping.
Demo
A few months ago, CVE-2024-21626 was disclosed. This vulnerability score is 8.6 (HIGH). It allows an attacker to escape a container and read/write to any path on the node and other pods hosted on the same node.
Rodrigo created a demo that exploits CVE 2024-21626 and shows how the exploit, which works without user namespaces, is mitigated when user namespaces are in use.
Please note that with user namespaces, an attacker can do on the host file system what the permission bits for "others" allow. Therefore, the CVE is not completely prevented, but the impact is greatly reduced.
Node system requirements
There are requirements on the Linux kernel version and the container runtime to use this feature.
On Linux you need Linux 6.3 or greater. This is because the feature relies on a kernel feature named idmap mounts, and support for using idmap mounts with tmpfs was merged in Linux 6.3.
Suppose you are using CRI-O with crun; as always, you can expect support for Kubernetes 1.30 with CRI-O 1.30. Please note you also need crun 1.9 or greater. If you are using CRI-O with runc, this is still not supported.
Containerd support is currently targeted for containerd 2.0, and the same crun version requirements apply. If you are using containerd with runc, this is still not supported.
Please note that containerd 1.7 added experimental support for user namespaces, as implemented in Kubernetes 1.25 and 1.26. We did a redesign in Kubernetes 1.27, which requires changes in the container runtime. Those changes are not present in containerd 1.7, so it only works with user namespaces support in Kubernetes 1.25 and 1.26.
Another limitation of containerd 1.7 is that it needs to change the ownership of every file and directory inside the container image during Pod startup. This has a storage overhead and can significantly impact the container startup latency. Containerd 2.0 will probably include an implementation that will eliminate the added startup latency and storage overhead. Consider this if you plan to use containerd 1.7 with user namespaces in production.
None of these containerd 1.7 limitations apply to CRI-O.
How do I get involved?
You can reach SIG Node by several means:
You can also contact us directly:
- GitHub: @rata @giuseppe @saschagrunert
- Slack: @rata @giuseppe @sascha